
n8nによる「本格的ワークフロー」のハンズオン第2回です。
前回は一連のハンズオンで作るもの・触れる内容についてのサマリーと、作成するワークフローの大まかな設計をお伝えしました。 (最初から読んでいただく場合はこちら)
今回からは実際に実装していきましょう。
n8nの管理画面から新しいワークフローを作成します。(Overview画面の右上『Create Workflow』から作成)
1. トリガーの設置
白紙のキャンバスにトリガーを置いていきましょう。
トリガーは何でもOKですが、今回は特に処理スタート時にパラメータ入力などが必要ないので、管理画面から「Execute workflow」をクリックする方式で行きます。
(WebhookやChatをトリガーにするなど、ここは何でもOKです。)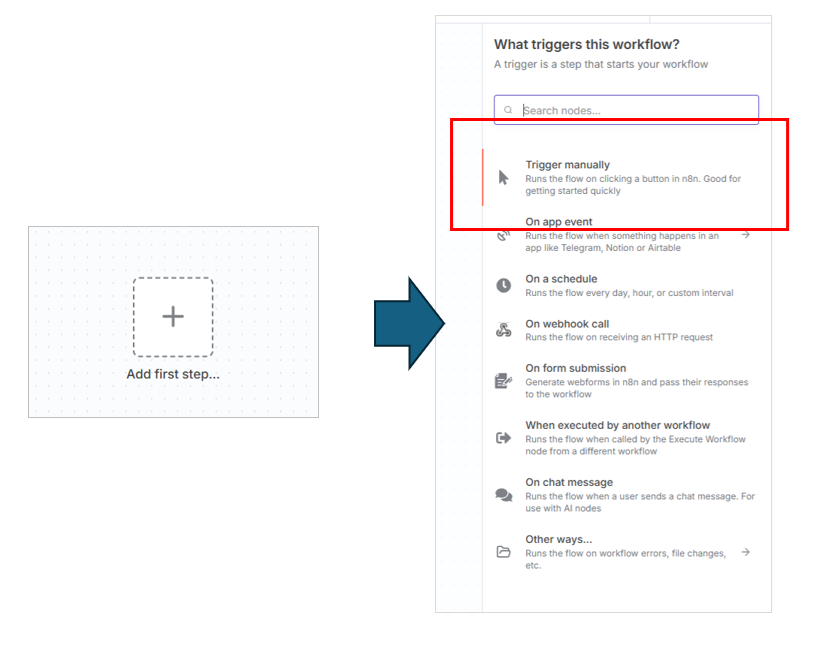
Add first step... をクリックして、「Trigger manually」を選択します。
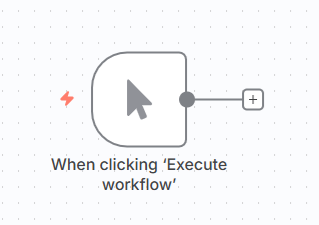
こちらのトリガーノードは「Execute workflow」をクリックすれば発動するシンプルなものなので、特に設定等は不要です。
2. HTTP Requestノード:目的サイトからHTMLを取得
トリガーノードに直結する形で、最初のアクションノードを設置しましょう。
ノードから伸びている「+」をクリックし、「HTTP Request」を選択します。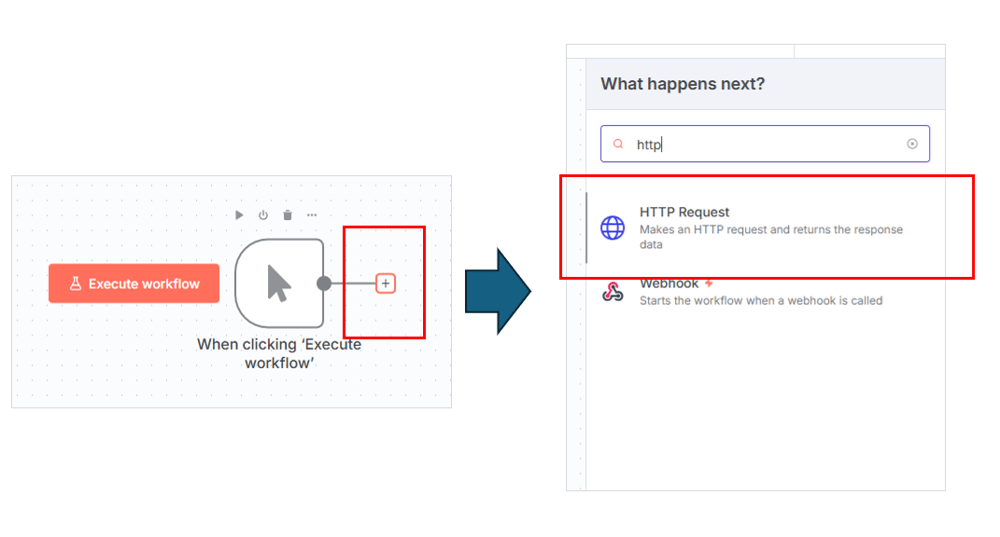
HTTP Request ノードを設置すると、設定画面が開きます。
下記のように設定してみましょう。
- Method:GET
- URL:ブログ記事を取得したいサイト。一覧ページなど。
(今回は、本ブログのURLを設定:https://blog.future.ad.jp/) - Send Headers:ON
- Header Parameters - Name:User-Agent
- Value:Mozilla/5.0 (compatible; n8n-scraper; +https://example.com/)
※ Headerはマナーとして指定。n8nからのスキャン目的と判別出来るように)
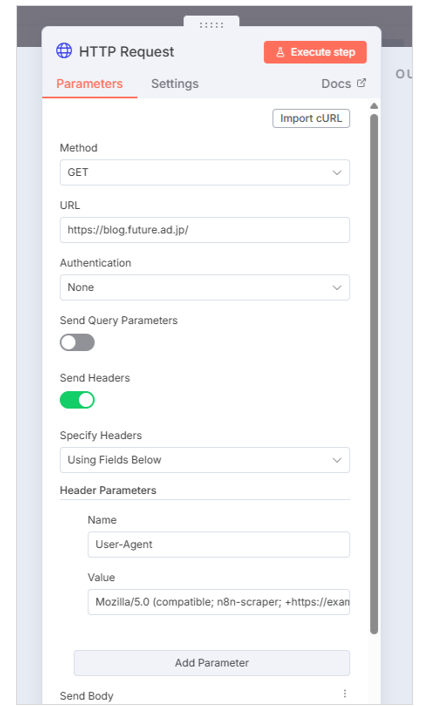
試しに「Execute Step」 をクリックすると、トリガーノードが引かれて、このノードまでのアクションが実行されます。
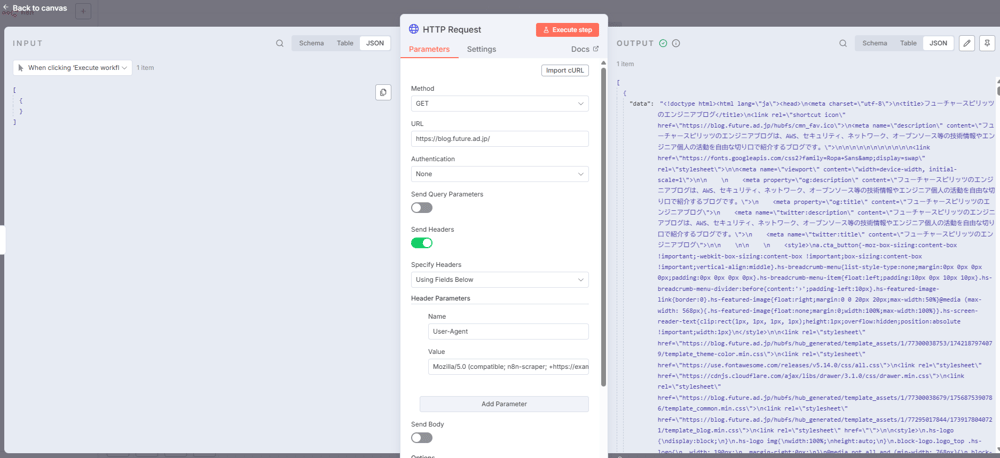
このように、HTMLがレスポンスとして取得できていればOKです。
3. HTMLノード:HTMLをparseする
次にHTTP Request で受け取ったHTMLソースを、HTMLノードに渡してparseします。
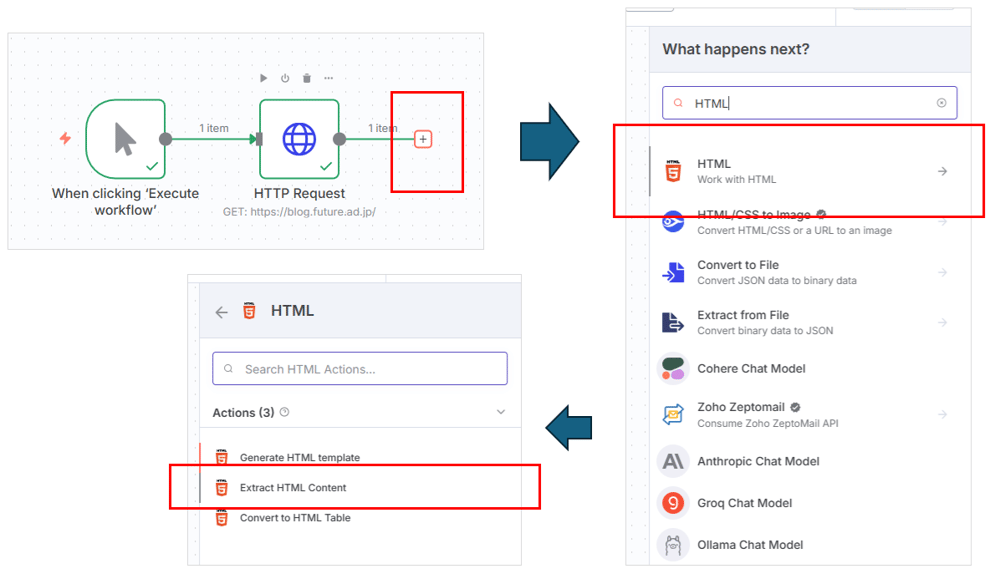
HTTP Requestノードにつなげる形で、HTMLノードを設置します。
設置するHTMLノードの種類を問われますので、今回は「Extract HTML Content」を選択します。
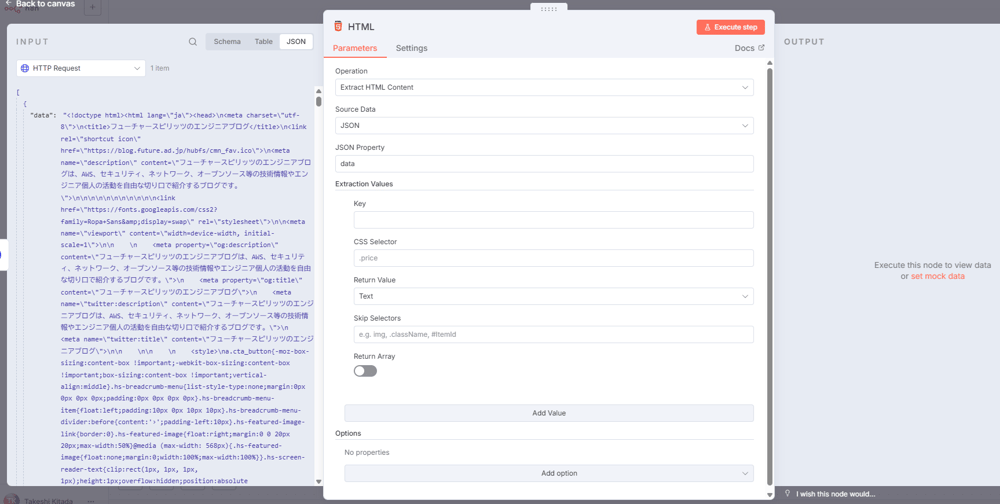
このように「左側に入力」「真ん中にカレントノードの設定・挙動記述」「右側に出力」という構図で挙動を確認しながら設定をしていきます。
この例では左側に「HTTP Requestノードの出力」を、「HTMLノードの入力値」として受け取っています。
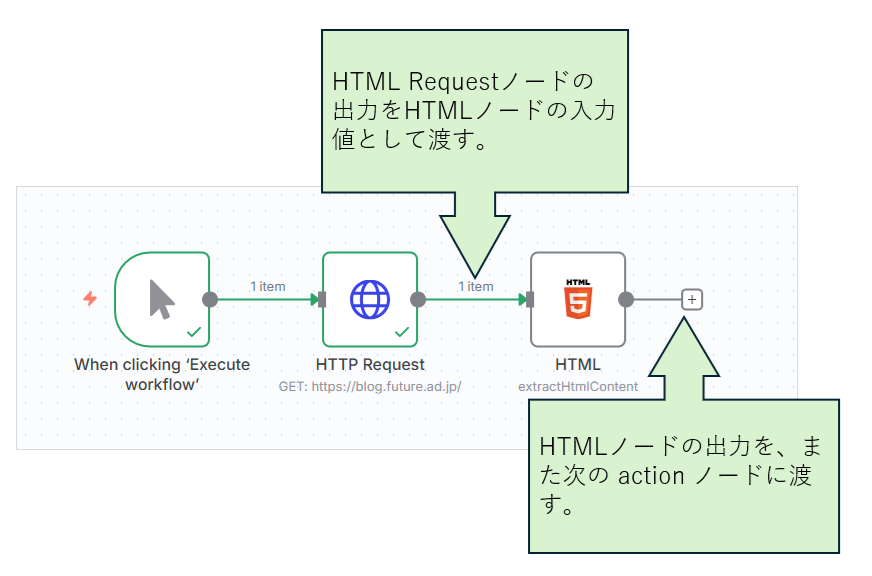
n8nではこのように、前のノードの処理結果・出力を、入力値として受取、「そのノードでやるべきこと」を実行した上で出力を、また次のアクションノードに入力値として渡す。ということを繰返してワークフローが進行していきます。
parseの方針を考える
ブログのトップや一覧に上がっている「新着記事群」を取得するために、サムネイルなどが表示された記事ブロックを特定して情報を取得していく必要があります。
n8nのHTMLノードではHTMLソースコードから、cssセレクタでDOMノードを特定し、オブジェクトやデータなどを抽出することができます。
ただし、1つのHTMLノードで複雑なparseを行うのは困難であったりワークフローの見通しを悪くする場合があるので、今回は下図のように、2段階に分けてparseを実施します。
1. まず、記事ごとにブロックでHTMLを取得する。=ブロックHTML入ったの配列を取得
2. HTML配列を再parseして、メタ情報を記事単位で取得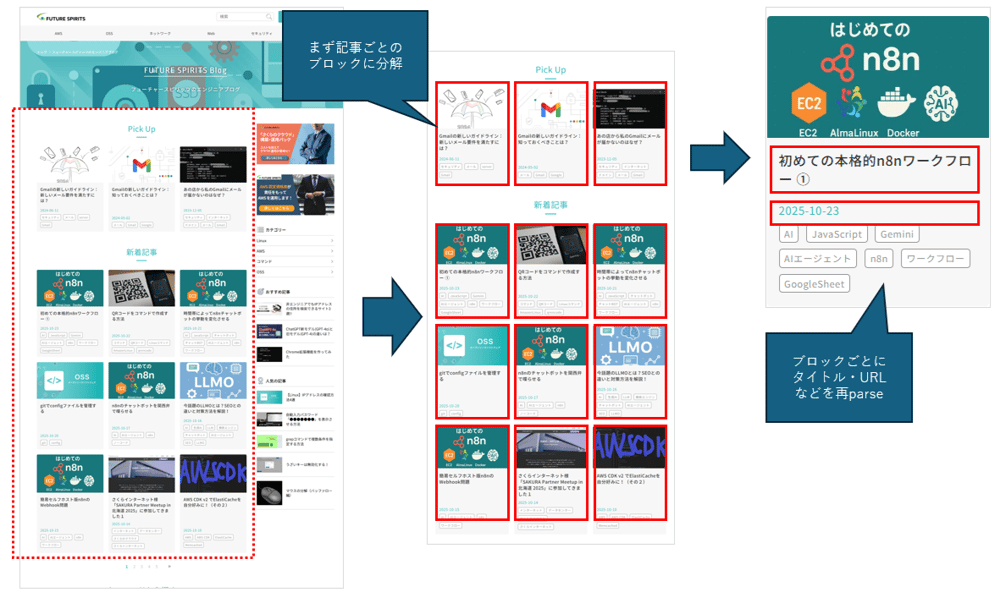
もちろん、Codeノードなどで、複雑なparse処理を独自で記述することも可能ですが、今回はn8nを理解することも目的なので、n8nが用意しているノードで出来ることは、なるべくn8nにまかせて行きます。
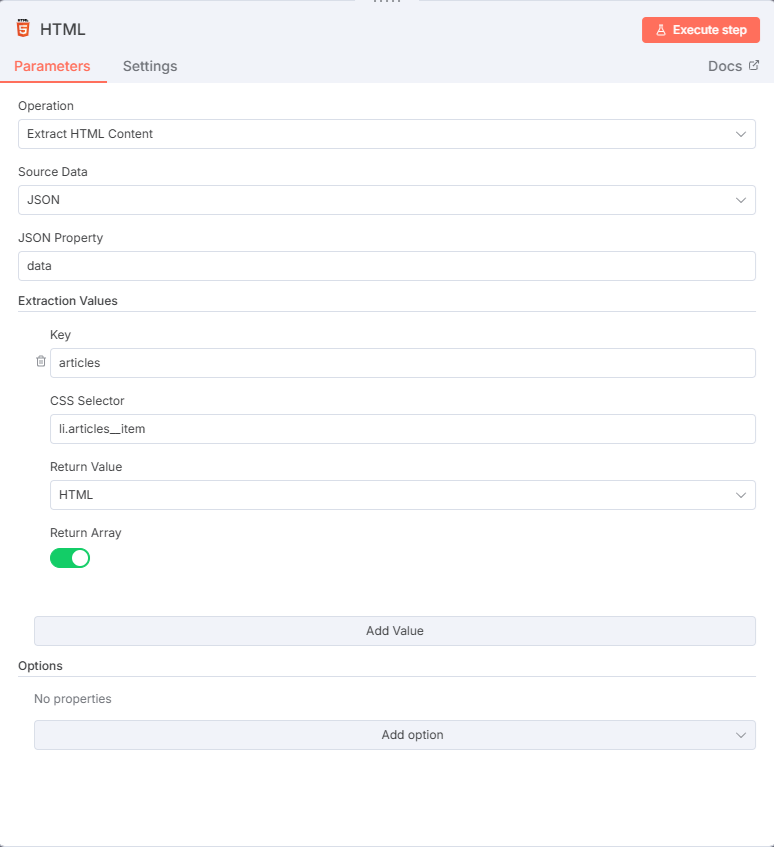
HTMLノードの設定
下記のように設定していきましょう。
- Source Data:JSON
- JSON Property:data
Extraction Values
- Key:articles
※ お好みの変数名でOK。後続ノードで利用します。 - CSS Selector:li.articles__item
※ 当ブログをターゲットとする場合。
※ ブログ記事1つ分のサムネイル表示のブロックDivのClass指定です。 - Return Value:HTML
- Return Array:ON
※ ONにすることで、記事単位のHTMLが配列で格納されます。
※ CSSセレクタの値やparseの方針は、当ブログの場合です。スクレイピングは今回のメイントピックではないので、ターゲットとするサイトの解析については、ブラウザの開発ツールなどを用いて適宜実施して下さい。
4. 2つめのHTMLノード:ブロックごとのparse
先程のHTMLノードに直結する形で、2つ目のHTMLノードを設置します。
例によってHTMLノードの設定が開くので、下記のように設定していきましょう。
- Source Data:JSON
- JSON Property:articles
Extraction Values 3つ分(タイトル・URL・公開日付)
まず、1つ目。
- Key:articleTitle
- CSS Selector:div.postlink__content__title h4
- Return Value:HTML
- Return Array:OFF
1つめのExtraction Value を設定したあと、「Add Value」をクリックすると、入力領域が拡張されて2つ目以降の設定を順次入力できるようになります。
2つ目を入力します。
- Key:articleURL
- CSS Selector:div.postlink__content__title a
- Return Value:href
- Return Array:OFF
続けてAdd Valueして3つ目も入力します
- Key:articleDate
- CSS Selector:div.postlink__content__date
- Return Value:TEXT
- Return Array:OFF
参考までに、1つ目のHTMLノードで、記事サムネイル群をparseしたHTMLノードの結果は下記のような入れ子構造の配列として出力されています。そのため、2つ目のHTMLノードではJSON Propertyにdataではなく"articles"を指定します。
[
{
"articles" : [
"( 1番めのブロックのHTML)",
"( 2番めのブロックのHTML)",
"( 3番めのブロックのHTML)",
"( 4番めのブロックのHTML)",
・・・・
"(n 番めのブロックのHTML)"
}
]
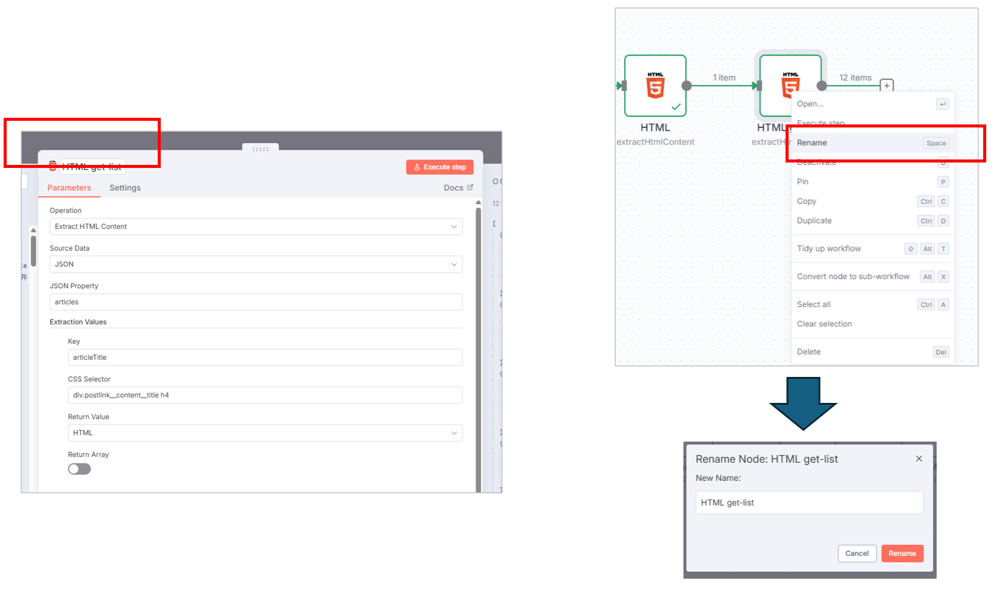
HTMLノードが続いてキャンバス上の見通しが悪くなるので、ついでにHTMLノードの名前を変更しておきましょう。
(HTMLノードに限らず)ノードの名前の変更には2つほどやり方があります。どちらでも大丈夫です。
- ノードの設定ダイアログの左上、名前部分をダブルクリックして変更する
- キャンバス画面でノードを右クリックし「Rename」を選択して、名前変更ダイアログで変更する。
試運転してみる
ここまでの設定をしたうえで、試しに「Execute Step」を実行すると、右辺にここまでの設置済みワークフローの結果が出力されます。
次のように、目的の値が取れていればOKです。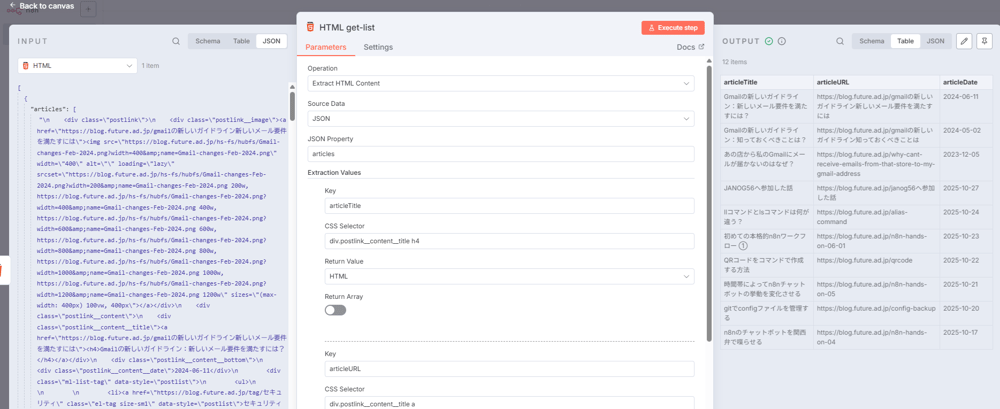 parse後は下記のように、ブロックごとに連想配列でまとまった、扱いやすい配列が、出力値として得られます。
parse後は下記のように、ブロックごとに連想配列でまとまった、扱いやすい配列が、出力値として得られます。
[
{ // 1番めのブロックのparse済情報のHash
"articleTitle": "Gmailの新しいガイドライン:新しいメール要件を満たすには?",
"articleURL": "https://blog.future.ad.jp/gmailの新しいガイドライン新しいメール要件を満たすには",
"articleDate": "2024-06-11"
},
{ // 2番めのブロックのparse済情報のHash
・・・・
},
・・・・
{ // n番めのブロックのparse済情報のHash
・・・・
}
]
ここまでの設定で、キャンバスは次のような状態になっているはずです。
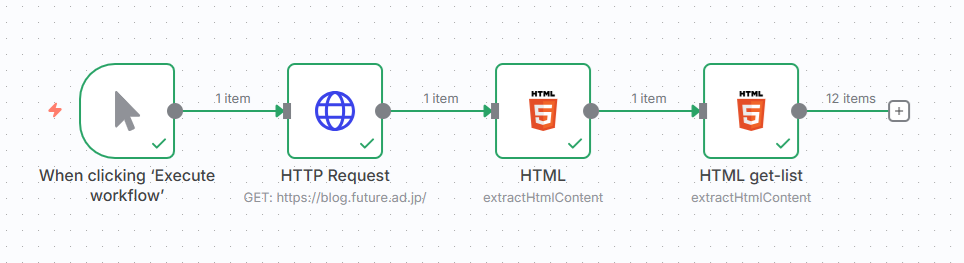
ここまでのワークフロー処理を見てみると、ブログ記事を単一のデータ(1 item) として処理する段階から始まり、2つめのHTMLノードを通ったあと、12 itemsになっていて、データが暗黙的にループ処理されたことがわかります。
これは、1つ目のHTMLノードの出力が、2階層目で「articles」という配列値を持っていて、2つ目のHTMLノードで「articles」を入力値として扱うように指定することで、暗黙的なループ処理が行われるn8nの仕様です。
明示的なループを行う「Loopノード」については次回以降で解説していきます。また、明示的にデータを分割する「Split Outノード」についても、派生的な解説として、別の機会に解説をします。
記事が長くなってきたので、今回はここまでにしましょう。
次回はCodeノードの使い方を解説していきます。
- トリガーの設置【Done:今回解説】
- 特定のURLから内容を取得する ▶ HTTP Request ノード【Done:今回解説】
- HTMLから要素を部会・取得する ▶ HTMLノード【Done:今回解説】
- 配列データの扱い方と暗黙的ループ処理【Done:今回解説】
- コードによる自由な処理 ▶ Codeノード → NEXT
- 明示的なループ処理 ▶ Loopノード
- フィールド生成・制御 ▶ MakeFieldsノード
- AIノードへの情報連携 ▶ Basic LLM Chain
- 処理済みの任意ノードの値の活用する
- Googleスプレッドシートへのレコード出力 ▶ Google Sheetノード
- Google Sheet API への アクセス許可の手順 ▶ Google Sheets account 設定
