
前回までで、セルフホスト版n8nをインストールして、単純なノードの扱い方やJavaScriptコードの仕込み方などを見てきました。
今回からはより実践的なワークフローの作成を目指します。
ゴール:出来上がるもの
- 特定のブログ記事から新着記事を一定数取得する
- スクレイピングをしてタイトル・公開日・本文・カテゴリなどを取得する
- 本文をAIで要約する
- 結果を記事単位で1レコードとして、スプレッドシートに出力する
ワンクリックでこのように動作するようにn8nでワークフローを作成していきます。
前回までよりもかなり多くのノードや設定を行っていきますので、数回の連載で解説していきます。
この連載で紹介する内容
- 特定のURLから内容を取得する ▶ HTTP Request ノード
- HTMLから要素を部会・取得する ▶ HTMLノード
- 配列データの扱い方と暗黙的ループ処理
- 明示的なループ処理 ▶ Loopノード
- コードによる自由な処理 ▶ Codeノード
- フィールド生成・制御 ▶ Edit Fieldsノード
- AIノードへの情報連携 ▶ Basic LLM Chain
- 処理済みの任意ノードの値の活用する
- Googleスプレッドシートへのレコード出力 ▶ Google Sheetノード
- Google Sheet API への アクセス許可の手順 ▶ Google Sheets account 設定
作成するワークフローの全容
先に全貌を見ておきましょう。
今回作成するワークフローは n8n キャンバスでは次の図のようなものになります。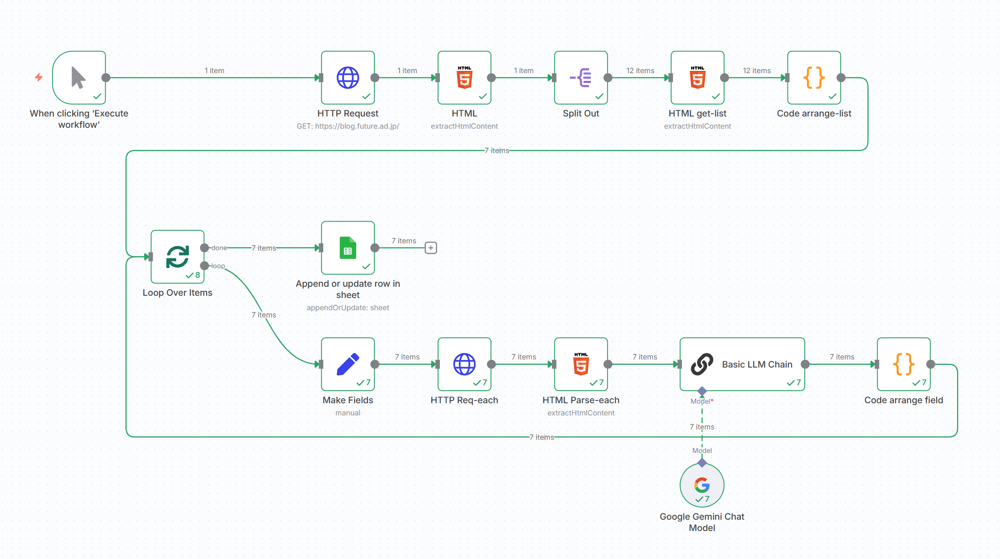
記事を取得する対象のサイトは、本ブログ:https://blog.future.ad.jp/ です。
上記のワークフローを実行すると、次のように最新の記事がGoogleスプレッドシートに書き込まれます。SummaryはGeminiによりAIで内容を要約したものです。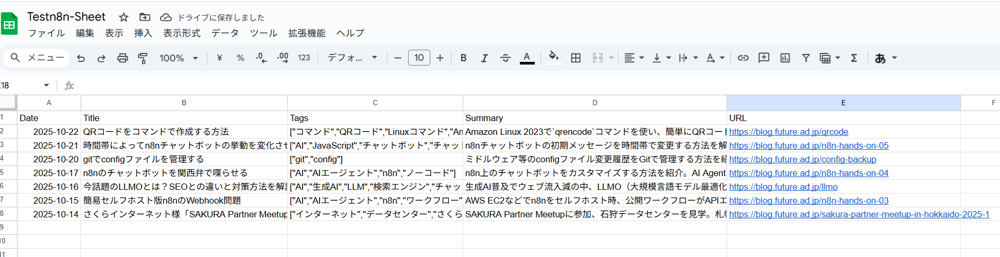
大まかな設計
想定する処理フローを大まかに図示すると下記のようなものになります。
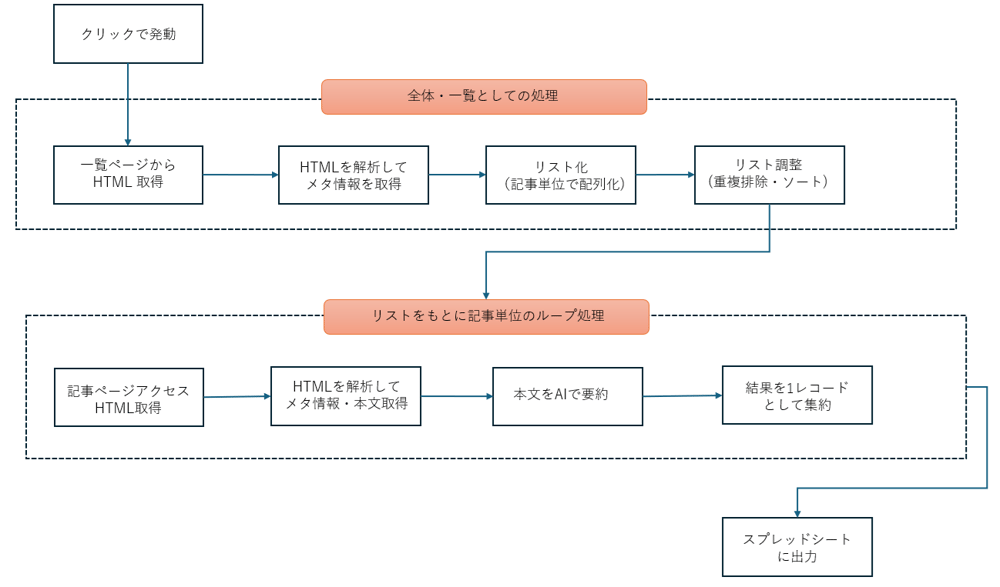
- 新着などがサムネイル・タイトルで並んでいる一覧系ページ(トップ)からHTML取得
- DOMノードを解析して「記事」ブロック単位に分解→メタ情報を取得・リスト化
- この時点で重複を除外してソートも実施
- リストをもとに、各記事にアクセス、本文などより詳細のデータを取得
- 本文をAIで要約
- 取得したデータを集約して「1レコード分」のデータとして生成
- 最終的にできたリストをスプレッドシートに出力
n8n要素と設計内容の照らし合わせ
ここまでの「設計」を n8nの要素に簡単に当てはめてみると以下のようになります。
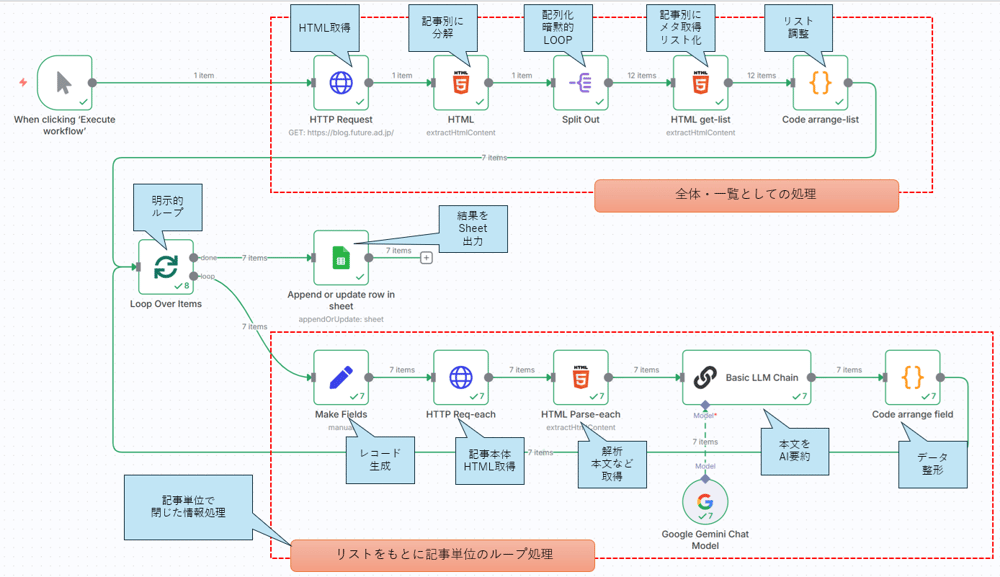 次回以降、この内容のモノを作り上げて行きながら、n8nのノードや使い方をより深く、順次解説して行きます。
次回以降、この内容のモノを作り上げて行きながら、n8nのノードや使い方をより深く、順次解説して行きます。
