
ハイ。M10iです。
機械学習を使って型抜きクッキーの効率化
の続きでございます。前回の予告どおり
やっと!機械学習ですよ!!お待たせしました!!
さっそく機械学習モデルを作っていきたいと思います。
が。機械学習モデルはたくさんあって、そのうちのどのモデルは何を使うのか?
ってところで、今回は深層強化学習モデルを使います。
強化学習モデルの特徴をざっと説明↓↓
目的は微調整をしつつ隙間を埋めてクッキー生地の無駄をなくしたい。
ってなると、この中ではPPOが相性が良さそうです。では早速コードを書いていきますが
その前に!そもそも強化学習っていうのは
AIさんに状態を確認しながら決められた行動を取ってもらって、いい感じの場合報酬を与える。
そして報酬を最大化するようにAIさんが最適な行動を学習する。
です!簡単!!(※ほんとはモデルによってQ値とか価値とかあるけど要約)
なので先にざっくりと行動と報酬と状態を定義しますね。
行動
クッキーの型を抜く。当たり前ですねw
ここでは抜く位置(x、y)と☆の回転を指定します。
報酬
型同士が重ならないように抜く。+1点
型同士が重なってしまうので抜けない。ー1点
抜いた位置が前の抜いた位置に近い。+α
状態
クッキーの生地
生地がある状態を0、抜かれた状態を1で表現。今回200px × 300px
とりあえず、イメージが大事なのでコードにします。
ちょっと長いけど大事なのはstepだけですw
※今回画面サイズとの兼ね合いもあって☆は綺麗なマップで作り直しました。
1pxがだいたい1mmのイメージで☆は3cm弱なるようにポリゴン調節してます。
cookie_cutter_env.py
stepで何をしてるかの説明
指定された位置(x,y)と回転(12°ずつ1回転分0~6で指定可能)で配置できるか?
→配置できた場合
配置OK =1点
さらに密集度+α
→配置できなかった場合
空スペースあり=マイナス1点、試行回数を増やして継続
空スペースがない→エピソードが終了
なんともざっくりとした行動と報酬です。いろいろ突っ込みどころはありますが
これを強化学習する前に、どんな感じで動くのか確認してみましょう
cookie_cutter.py
def render(env):
# JSON ファイルのパス
# 初回描画
ここでは100回ランダムでお試しで実行しますが、本来はdone==Trueになるまで試行し学習するはずです。
そこまでを1つのサイクルとして、だいたい1万step~学習してもらいます。
繰り返すうちに報酬が高くなるようにactionを選択するようになります(願望)
初回描画
なにもしてない状態ですね。
1pxを1mmとしたイメージで、20cm×30cmの生地です。
100回後
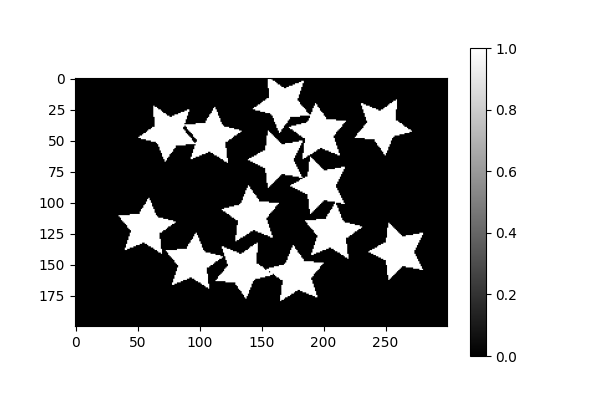
わりと自由に型抜きしますねw
学習するともっと良くなるのか不安ですね、まるでうちの子供のようだwwww
では早速SageMakerに乗っけて学習させていきたいと思います。
え?長い?
でもさっきのコードを学習してねってお願いするだけなので、実はコードはとても簡単。
いよいよ機械学習ですよ!!!!!
train.py
json_path = "polygon_data.json"
学習コードです。polygon_data.jsonは☆の型をそのまま置いてます。
PPOモデルをさっきのコード(cookie_cutter_env.py)で、100000stepほど学習してもらいます。
cookie_cutter_model.zipが出力されたら学習完了です!
ちょっと学習ログの見方をご紹介。※verbose=2に設定するとlearn中に出力してくれます。
| rollout/ | ||
| ep_len_mean | 117 | エピソード終了までの平均Step数 |
| ep_rew_mean | -53 | エピソード終了時の平均報酬 |
| time/ | ||
| total_timesteps | 2048 | 総学習Step数 |
| train/ | ||
| explained_variance | 0.0921 | データからAIが予測するActionがどれだけ報酬をもらえるか?を-1~1で表現 |
てことで、ep_len_meanはまずまず。しかしそれに対して
ep_rew_meanが-53と報酬がものすごく低いのがわかります。
explained_varianceもほぼ0なので予測しても報酬が受け取れてません。
このあんまり報酬のもらえなかった子に、予測をしてもらいます(嫌な予感しかないw)
test.py
from stable_baselines3 import PPO
import matplotlib.pyplot as plt
from cookie_cutter_env import CookieCutterEnv
# 環境を作成
env = CookieCutterEnv(json_path="polygon_data.json")
obs, _ = env.reset()
# 学習済みモデルのロード
model = PPO.load(f"cookie_cutter_model.zip")
実験と同じで100回実行します。
結果・・・・・・
なんと!!!!!ランダムで出すよりもひどいwwwwwww
ちなみにログですが、1回目〇、2回目〇、3回目でNG
その後NGにかかわらず3回目と同じ値をずーーーっとだします。
2回目付近なのでうまく入れば報酬をもらえるはずなのはわかるのですが交差ペナルティが無いせいか頑なに選んでますね。
Reward: 1
2回目:AAction Taken: [139 109 2]
Reward: 3.0738250223200922
3回目:AAction Taken: [139 77 2]
Reward: -1
4回目:Action Taken: [139 77 2]
Reward: -1
~以下ずっと同じ[139 77 2]~
deterministic=Trueだと再現性が強過ぎるのかもしれません。
Falseで実行してみると・・・・
最初のランダムと似てますねw
☆が16個に増えたので、ランダムより打率は良いかもしれませんっ
今回はちょっと残念な形になってしました。。。。。。
では、終わる前に反省点を。。。。。
問題点
状態(State(観測空間)が 0,1 の配列のみ)
現在状態 は「型抜きが終わった 0,1 の配列」なので情報が少なすぎるかも?
- どの部分に空きスペースがあるのか?
- どの場所に配置すると密集度が高くなるか?
- どれくらいのスペースが残っているのか?
この辺りを考慮しないといけないですよね。
報酬(rewardが -1, 1のみ)
追加報酬ほぼ意味無し、ペナルティの方が強すぎて報酬が得れてませんwwww
あと報酬が増えないので学習が進んでませんw
置いてもペナルティばっかりじゃどこに置くかなんてわかんないデスヨネー
学習中から何となくわかってた事ですが、結果を出してみるとより歴然としましたね。
最低でも以下は改善しないとダメだと思われます。
- 既存と交差した時のペナルティがない
- 配置できた時の報酬が低い
終わりに
型取りから機械学習までひととおり実行してみましたが、いかがだったでしょう?
M10iはとりあえず作ってみてから考える派なので、次回!!!!
~~~~~もっと精度を上げてみよう~~~~~~
に続きたいと思いますw
M10iでしたっ
